应用程序性能直接受到垃圾收集(GC)的频率和持续时间的影响,如果在GC策略调优到达瓶颈后,性能的差别就会产生在代码的编写质量了。下面就来说说GC友好代码的几个技巧。
技巧1:预测收集容量
所有标准Java集合,以及大多数自定义和扩展实现(如Trove和Google的Guava)都使用底层数组(基于原语或基于对象)。由于数组在分配后大小是不可变的,因此在许多情况下,向集合中添加项可能会导致删除旧的底层数组,而选择新分配的较大数组。
大多数集合实现都试图优化此重新分配过程,并将其保持在摊销最小值,即使未提供集合的预期大小。但是,通过在构建时为集合提供其预期大小,可以实现最佳效果。
技巧2:直接处理流程
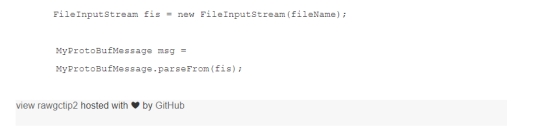
在处理数据流时,例如从文件读取的数据或通过网络下载的数据,通常会看到以下内容:

然后,可以将生成的字节数组解析为XML文档、JSON对象或协议缓冲区消息,以列举一些流行选项。
在处理大型文件或大小不可预测的文件时,这显然是一个坏主意,因为如果JVM无法实际分配整个文件大小的缓冲区,它会使我们暴露出OutOfMemory错误。
更好的方法是使用适当的InputStream(本例中为FileInputStream)并将其直接提供给解析器,而无需首先将整个内容读入字节数组。所有主要库都公开API以直接解析流,例如:
技巧3:使用不可变对象
不变性有许多优点。它对垃圾收集的影响很少得到应有的关注。
不可变对象是一个对象,其字段(在本例中特别是非基本字段)在对象构造后无法修改。
不变性意味着不可变容器引用的所有对象都是在容器构造完成之前创建的。在GC术语中:容器至少和它所持有的最年轻引用一样年轻。这意味着,当对年轻代执行垃圾收集循环时,GC可以跳过位于较老代中的不可变对象,因为它确定这些对象不能引用正在收集的代中的任何对象。
要扫描的对象越少意味着要扫描的内存页越少,而要扫描的内存页越少意味着GC周期越短,这意味着GC暂停时间越短,总体吞吐量越好。





发表评论 取消回复